Закон распределения хи квадрат. Распределение Пирсона (распределение хи-квадрат)
До конца XIX века нормальное распределение считалась всеобщим законом вариации данных. Однако К. Пирсон заметил, что эмпирические частоты могут сильно отличаться от нормального распределения. Встал вопрос, как это доказать. Требовалось не только графическое сопоставление, которое имеет субъективный характер, но и строгое количественное обоснование.
Так был изобретен критерий χ 2 (хи квадрат), который проверяет значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Это произошло в далеком 1900 году, однако критерий и сегодня на ходу. Более того, его приспособили для решения широкого круга задач. Прежде всего, это анализ категориальных данных, т.е. таких, которые выражаются не количеством, а принадлежностью к какой-то категории. Например, класс автомобиля, пол участника эксперимента, вид растения и т.д. К таким данным нельзя применять математические операции вроде сложения и умножения, для них можно только подсчитать частоты.
Наблюдаемые частоты обозначим О (Observed) , ожидаемые – E (Expected) . В качестве примера возьмем результат 60-кратного бросания игральной кости. Если она симметрична и однородна, вероятность выпадения любой стороны равна 1/6 и, следовательно, ожидаемое количество выпадения каждой из сторон равна 10 (1/6∙60). Наблюдаемые и ожидаемые частоты запишем в таблицу и нарисуем гистограмму.

Нулевая гипотеза заключается в том, что частоты согласованы, то есть фактические данные не противоречат ожидаемым. Альтернативная гипотеза – отклонения в частотах выходят за рамки случайных колебаний, расхождения статистически значимы. Чтобы сделать строгий вывод, нам потребуется.
- Обобщающая мера расхождения между наблюдаемыми и ожидаемыми частотами.
- Распределение этой меры при справедливости гипотезы о том, что различий нет.
Начнем с расстояния между частотами. Если взять просто разницу О — E , то такая мера будет зависеть от масштаба данных (частот). Например, 20 — 5 =15 и 1020 – 1005 = 15. В обоих случаях разница составляет 15. Но в первом случае ожидаемые частоты в 3 раза меньше наблюдаемых, а во втором случае – лишь на 1,5%. Нужна относительная мера, не зависящая от масштаба.
Обратим внимание на следующие факты. В общем случае количество категорий, по которым измеряются частоты, может быть гораздо больше, поэтому вероятность того, что отдельно взятое наблюдение попадет в ту или иную категорию, довольно мала. Раз так, то, распределение такой случайной величины будет подчинятся закону редких событий, известному под названием закон Пуассона . В законе Пуассона, как известно, значение математического ожидания и дисперсии совпадают (параметр λ ). Значит, ожидаемая частота для некоторой категории номинальной переменной E i будет являться одновременное и ее дисперсией. Далее, закон Пуассона при большом количестве наблюдений стремится к нормальному. Соединяя эти два факта, получаем, что, если гипотеза о согласии наблюдаемых и ожидаемых частот верна, то, при большом количестве наблюдений , выражение
Важно помнить, что нормальность будет проявляться только при достаточно больших частотах. В статистике принято считать, что общее количество наблюдений (сумма частот) должна быть не менее 50 и ожидаемая частота в каждой градации должна быть не менее 5. Только в этом случае величина, показанная выше, имеет стандартное нормальное распределение. Предположим, что это условие выполнено.
У стандартного нормального распределения почти все значение находятся в пределах ±3 (правило трех сигм). Таким образом, мы получили относительную разность в частотах для одной градации. Нам нужна обобщающая мера. Просто сложить все отклонения нельзя – получим 0 (догадайтесь почему). Пирсон предложил сложить квадраты этих отклонений.
![]()
Это и есть знамений критерий Хи-квадрат Пирсона . Если частоты действительно соответствуют ожидаемым, то значение критерия будет относительно не большим (т.к. большинство отклонений находится около нуля). Но если критерий оказывается большим, то это свидетельствует в пользу существенных различий между частотами.
«Большим» критерий Пирсона становится тогда, когда появление такого или еще большего значения становится маловероятным. И чтобы рассчитать такую вероятность, необходимо знать распределение критерия при многократном повторении эксперимента, когда гипотеза о согласии частот верна.
Как нетрудно заметить, величина хи-квадрат также зависит от количества слагаемых. Чем их больше, тем большее значение должно быть у критерия, ведь каждое слагаемое внесет свой вклад в общую сумму. Следовательно, для каждого количества независимых слагаемых, будет собственное распределение. Получается, что χ 2 – это целое семейство распределений.
И здесь мы подошли к одному щекотливому моменту. Что такое число независимых слагаемых? Вроде как любое слагаемое (т.е. отклонение) независимо. К. Пирсон тоже так думал, но оказался неправ. На самом деле число независимых слагаемых будет на один меньше, чем количество градаций номинальной переменной n . Почему? Потому что, если мы имеем выборку, по которой уже посчитана сумма частот, то одну из частот всегда можно определить, как разность общего количества и суммой всех остальных. Отсюда и вариация будет несколько меньше. Данный факт Рональд Фишер заметил лет через 20 после разработки Пирсоном своего критерия. Даже таблицы пришлось переделывать.
По этому поводу Фишер ввел в статистику новое понятие – степень свободы (degrees of freedom), которое и представляет собой количество независимых слагаемых в сумме. Понятие степеней свободы имеет математическое объяснение и проявляется только в распределениях, связанных с нормальным (Стьюдента, Фишера-Снедекора и сам хи-квадрат).
Чтобы лучше уловить смысл степеней свободы, обратимся к физическому аналогу. Представим точку, свободно движущуюся в пространстве. Она имеет 3 степени свободы, т.к. может перемещаться в любом направлении трехмерного пространства. Если точка движется по какой-либо поверхности, то у нее уже две степени свободы (вперед-назад, вправо-влево), хотя и продолжает находиться в трехмерном пространстве. Точка, перемещающаяся по пружине, снова находится в трехмерном пространстве, но имеет лишь одну степень свободы, т.к. может двигаться либо вперед, либо назад. Как видно, пространство, где находится объект, не всегда соответствует реальной свободе перемещения.
Примерно также распределение статистического критерия может зависеть от меньшего количества элементов, чем нужно слагаемых для его расчета. В общем случае количество степеней свободы меньше наблюдений на число имеющихся зависимостей.
Таким образом, распределение хи квадрат (χ 2 ) – это семейство распределений, каждое из которых зависит от параметра степеней свободы. А формальное определение критерия хи-квадрат следующее. Распределение χ 2 (хи-квадрат) с k степенями свободы - это распределение суммы квадратов k независимых стандартных нормальных случайных величин.
Далее можно было бы перейти к самой формуле, по которой вычисляется функция распределения хи-квадрат, но, к счастью, все давно подсчитано за нас. Чтобы получить интересующую вероятность, можно воспользоваться либо соответствующей статистической таблицей, либо готовой функцией в Excel.
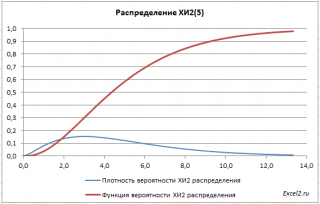
Интересно посмотреть, как меняется форма распределения хи-квадрат в зависимости от количества степеней свободы.

С увеличением степеней свободы распределение хи-квадрат стремится к нормальному. Это объясняется действием центральной предельной теоремы, согласно которой сумма большого количества независимых случайных величин имеет нормальное распределение. Про квадраты там ничего не сказано)).
Проверка гипотезы по критерию хи квадрат Пирсона
Вот мы и подошли к проверке гипотез по методу хи-квадрат. В целом техника остается . Выдвигается нулевая гипотеза о том, что наблюдаемые частоты соответствуют ожидаемым (т.е. между ними нет разницы, т.к. они взяты из той же генеральной совокупности). Если этот так, то разброс будет относительно небольшим, в пределах случайных колебаний. Меру разброса определяют по критерию хи-квадрат. Далее либо сам критерий сравнивают с критическим значением (для соответствующего уровня значимости и степеней свободы), либо, что более правильно, рассчитывают наблюдаемый p-value, т.е. вероятность получить такое или еще больше значение критерия при справедливости нулевой гипотезы.

Т.к. нас интересует согласие частот, то отклонение гипотезы произойдет, когда критерий окажется больше критического уровня. Т.е. критерий является односторонним. Однако иногда (иногда) требуется проверить левостороннюю гипотезу. Например, когда эмпирические данные уж оооочень сильно похожи на теоретические. Тогда критерий может попасть в маловероятную область, но уже слева. Дело в том, что в естественных условиях, маловероятно получить частоты, практически совпадающие с теоретическими. Всегда есть некоторая случайность, которая дает погрешность. А вот если такой погрешности нет, то, возможно, данные были сфальсифицированы. Но все же обычно проверяют правостороннюю гипотезу.
Вернемся к задаче с игральной костью. Рассчитаем по имеющимся данным значение критерия хи-квадрат.
Теперь найдем критическое значение при 5-ти степенях свободы (k ) и уровне значимости 0,05 (α ) по таблице критических значений распределения хи квадрат.

То есть квантиль 0,05 хи квадрат распределения (правый хвост) с 5-ю степенями свободы χ 2 0,05; 5 = 11,1.
Сравним фактическое и табличное значение. 3,4 (χ 2 ) < 11,1 (χ 2 0,05; 5 ). Расчетный критерий оказался меньшим, значит гипотеза о равенстве (согласии) частот не отклоняется. На рисунке ситуация выглядит вот так.

Если бы расчетное значение попало в критическую область, то нулевая гипотеза была бы отклонена.
Более правильным будет рассчитать еще и p-value. Для этого нужно в таблице найти ближайшее значение для заданного количества степеней свободы и посмотреть соответствующий ему уровень значимости. Но это прошлый век. Воспользуемся ЭВМ, в частности MS Excel. В эксель есть несколько функций, связанных с хи-квадрат.

Ниже их краткое описание.
ХИ2.ОБР – критическое значение критерия при заданной вероятности слева (как в статистических таблицах)
ХИ2.ОБР.ПХ – критическое значение критерия при заданной вероятности справа. Функция по сути дублирует предыдущую. Но здесь можно сразу указывать уровень α , а не вычитать его из 1. Это более удобно, т.к. в большинстве случаев нужен именно правый хвост распределения.
ХИ2.РАСП – p-value слева (можно рассчитать плотность).
ХИ2.РАСП.ПХ – p-value справа.
ХИ2.ТЕСТ – по двум диапазонам частот сразу проводит хи-квадрат тест. Количество степеней свободы берется на одну меньше, чем количество частот в столбце (так и должно быть), возвращая значение p-value.
Давайте пока рассчитаем для нашего эксперимента критическое (табличное) значение для 5-ти степеней свободы и альфа 0,05. Формула Excel будет выглядеть так:
ХИ2.ОБР(0,95;5)
ХИ2.ОБР.ПХ(0,05;5)
Результат будет одинаковым – 11,0705. Именно это значение мы видим в таблице (округленное до 1 знака после запятой).
Рассчитаем, наконец, p-value для 5-ти степеней свободы критерия χ 2 = 3,4. Нужна вероятность справа, поэтому берем функцию с добавкой ПХ (правый хвост)
ХИ2.РАСП.ПХ(3,4;5) = 0,63857
Значит, при 5-ти степенях свободы вероятность получить значение критерия χ 2 = 3,4 и больше равна почти 64%. Естественно, гипотеза не отклоняется (p-value больше 5%), частоты очень хорошо согласуются.
А теперь проверим гипотезу о согласии частот с помощью теста хи квадрат и функции Excel ХИ2.ТЕСТ.

Никаких таблиц, никаких громоздких расчетов. Указав в качестве аргументов функции столбцы с наблюдаемыми и ожидаемыми частотами, сразу получаем p-value. Красота.
Представим теперь, что вы играете в кости с подозрительным типом. Распределение очков от 1 до 5 остается прежним, но он выкидывает 26 шестерок (количество всех бросков становится 78).

p-value в этом случае оказывается 0,003, что гораздо меньше чем, 0,05. Есть серьезные основания сомневаться в правильности игральной кости. Вот, как выглядит эта вероятность на диаграмме распределения хи-квадрат.

Сам критерий хи-квадрат здесь получается 17,8, что, естественно, больше табличного (11,1).
Надеюсь, мне удалось объяснить, что такое критерий согласия χ 2 (хи-квадрат) Пирсона и как с его помощью проверяются статистические гипотезы.
Напоследок еще раз о важном условии! Критерий хи-квадрат исправно работает только в случае, когда количество всех частот превышает 50, а минимальное ожидаемое значение для каждой градации не меньше 5. Если в какой-либо категории ожидаемая частота менее 5, но при этом сумма всех частот превышает 50, то такую категорию объединяют с ближайшей, чтобы их общая частота превысила 5. Если это сделать невозможно, или сумма частот меньше 50, то следует использовать более точные методы проверки гипотез. О них поговорим в другой раз.
Ниже находится видео ролик о том, как в Excel проверить гипотезу с помощью критерия хи-квадрат.
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна
где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Распределение вероятных значений случайной величины χ2 непрерывно и ассиметрично. Оно зависит от числа степеней свободы (n) и приближается к нормальному распределению по мере увеличения числа наблюдений. Поэтому применение критерия χ2 к оценке дискретных распределений сопряжено с некоторыми погрешностями, которые сказываются на его величине, особенно на малочисленных выборках. Для получения более точных оценок выборка, распределяемая в вариационный ряд, должна иметь не менее 50 вариантов. Правильное применение критерия χ2 требует также, чтобы частоты вариантов в крайних классах не были бы меньше 5; если их меньше 5, то они объединяются с частотами соседних классов, чтобы в сумме составляли величину большую или равную 5. Соответственно объединению частот уменьшается и число классов (N). Число степеней свободы устанавливается по вторичному числу классов с учетом числа ограничений свободы вариации.
Так как точность определения критерия χ2 в значительной степени зависит от точности расчета теоретических частот (Т), для получения разности между эмпирическими и вычисленными частотами следует использовать неокругленные теоретические частоты.
В качестве примера возьмем исследование, опубликованное на сайте, который посвящен применению статистических методов в гуманитарных науках.
Критерий "Хи-квадрат" позволяет сравнивать распределения частот вне зависимости от того, распределены они нормально или нет.
Под частотой понимается количество появлений какого-либо события. Обычно, с частотой появления события имеют дело, когда переменные измерены в шкале наименований и другой их характеристики, кроме частоты подобрать невозможно или проблематично. Другими словами, когда переменная имеет качественные характеристики. Так же многие исследователи склонны переводить баллы теста в уровни (высокий, средний, низкий) и строить таблицы распределений баллов, чтобы узнать количество человек по этим уровням. Чтобы доказать, что в одном из уровней (в одной из категорий) количество человек действительно больше (меньше) так же используется коэффициент Хи-квадрат.
Разберем самый простой пример.
Среди младших подростков был проведён тест для выявления самооценки. Баллы теста были переведены в три уровня: высокий, средний, низкий. Частоты распределились следующим образом:
Высокий (В) 27 чел.
Средний (С) 12 чел.
Низкий (Н) 11 чел.
Очевидно, что детей с высокой самооценкой большинство, однако это нужно доказать статистически. Для этого используем критерий Хи-квадрат.
Наша задача проверить, отличаются ли полученные эмпирические данные от теоретически равновероятных. Для этого необходимо найти теоретические частоты. В нашем случае, теоретические частоты – это равновероятные частоты, которые находятся путём сложения всех частот и деления на количество категорий.
В нашем случае:
(В + С + Н)/3 = (27+12+11)/3 = 16,6
Формула для расчета критерия хи-квадрат:
χ2 = ∑(Э - Т)І / Т
Строим таблицу:
Находим сумму последнего столбца:
Теперь нужно найти критическое значение критерия по таблице критических значений (Таблица 1 в приложении). Для этого нам понадобится число степеней свободы (n).
n = (R - 1) * (C - 1)
где R – количество строк в таблице, C – количество столбцов.
В нашем случае только один столбец (имеются в виду исходные эмпирические частоты) и три строки (категории), поэтому формула изменяется – исключаем столбцы.
n = (R - 1) = 3-1 = 2
Для вероятности ошибки p≤0,05 и n = 2 критическое значение χ2 = 5,99.
Полученное эмпирическое значение больше критического – различия частот достоверны (χ2= 9,64; p≤0,05).
Как видим, расчет критерия очень прост и не занимает много времени. Практическая ценность критерия хи-квадрат огромна. Этот метод оказывается наиболее ценным при анализе ответов на вопросы анкет.
Разберем более сложный пример.
К примеру, психолог хочет узнать, действительно ли то, что учителя более предвзято относятся к мальчикам, чем к девочкам. Т.е. более склонны хвалить девочек. Для этого психологом были проанализированы характеристики учеников, написанные учителями, на предмет частоты встречаемости трех слов: "активный", "старательный", "дисциплинированный", синонимы слов так же подсчитывались. Данные о частоте встречаемости слов были занесены в таблицу:
Для обработки полученных данных используем критерий хи-квадрат.
Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем:
Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s).
Итоговая таблица для вычислений будет выглядеть так:
χ2 = ∑(Э - Т)І / Т
n = (R - 1), где R – количество строк в таблице.
В нашем случае хи-квадрат = 4,21; n = 2.
По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99.
Полученное значение меньше критического, а значит принимается нулевая гипотеза.
Вывод: учителя не придают значение полу ребенка при написании ему характеристики.
Заключение.
К. Пирсон внёс значительный вклад в развитие математической статистики (большое количество фундаментальных понятий). Основная философская позиция Пирсона формулируется следующим образом: понятия науки - искусственные конструкции, средства описания и упорядочивания чувственного опыта; правила связи их в научные предложения вычленяются грамматикой науки, которая и является, философией науки. Связать же разнородные понятия и явления позволяет универсальная дисциплина - прикладная статистика, хотя и она по Пирсону субъективна.
Многие построения К. Пирсона напрямую связаны или разрабатывались с использованием антропологических материалов. Им разработаны многочисленные способы нумерической классификации и статистические критерии, применяемые во всех областях науки.
Литература.
1. Боголюбов А. Н. Математики. Механики. Биографический справочник. - Киев: Наукова думка, 1983.
2. Колмогоров А. Н., Юшкевич А. П. (ред.). Математика XIX века. - М.: Наука. - Т. I.
3. 3. Боровков А.А. Математическая статистика. М.: Наука, 1994.
4. 8. Феллер В. Введение в теорию вероятностей и ее приложения. - М.: Мир, Т.2, 1984.
5. 9. Харман Г., Современный факторный анализ. - М.: Статистика, 1972.
Распределения Пирсона (хи – квадрат), Стьюдента и Фишера
С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных. В дальнейших разделах книги много раз встречаются эти распределения.
Распределение Пирсона (хи - квадрат) – распределение случайной величины
где случайные величины X 1 , X 2 ,…, X n независимы и имеют одно и тоже распределение N (0,1). При этом число слагаемых, т.е. n , называется «числом степеней свободы» распределения хи – квадрат.
Распределение хи-квадрат используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости, прежде всего для качественных (категоризованных) переменных, принимающих конечное число значений, и во многих других задачах статистического анализа данных .
Распределение t Стьюдента – это распределение случайной величины
где случайные величины U и X независимы, U имеет распределение стандартное нормальное распределение N (0,1), а X – распределение хи – квадрат с n степенями свободы. При этом n называется «числом степеней свободы» распределения Стьюдента.
Распределение Стьюдента было введено в 1908 г. английским статистиком В. Госсетом, работавшем на фабрике, выпускающей пиво. Вероятностно-статистические методы использовались для принятия экономических и технических решений на этой фабрике, поэтому ее руководство запрещало В. Госсету публиковать научные статьи под своим именем. Таким способом охранялась коммерческая тайна, «ноу-хау» в виде вероятностно-статистических методов, разработанных В. Госсетом. Однако он имел возможность публиковаться под псевдонимом «Стьюдент». История Госсета - Стьюдента показывает, что еще сто лет назад менеджерам Великобритании была очевидна большая экономическая эффективность вероятностно-статистических методов.
В настоящее время распределение Стьюдента – одно из наиболее известных распределений среди используемых при анализе реальных данных. Его применяют при оценивании математического ожидания, прогнозного значения и других характеристик с помощью доверительных интервалов, по проверке гипотез о значениях математических ожиданий, коэффициентов регрессионной зависимости, гипотез однородности выборок и т.д. .
Распределение Фишера – это распределение случайной величины
где случайные величины Х 1 и Х 2 независимы и имеют распределения хи – квадрат с числом степеней свободы k 1 и k 2 соответственно. При этом пара (k 1 , k 2 ) – пара «чисел степеней свободы» распределения Фишера, а именно, k 1 – число степеней свободы числителя, а k 2 – число степеней свободы знаменателя. Распределение случайной величины F названо в честь великого английского статистика Р.Фишера (1890-1962), активно использовавшего его в своих работах.
Распределение Фишера используют при проверке гипотез об адекватности модели в регрессионном анализе, о равенстве дисперсий и в других задачах прикладной статистики .
Выражения для функций распределения хи - квадрат, Стьюдента и Фишера, их плотностей и характеристик, а также таблицы, необходимые для их практического использования, можно найти в специальной литературе (см., например, ).
Количественное изучение биологических явлений обязательно требует создания гипотез, с помощью которых можно объяснить эти явления. Чтобы проверить ту или иную гипотезу ставят серию специальных опытов и полученные фактические данные сопоставляют с теоретически ожидаемыми согласно данной гипотезе. Если есть совпадениеэто может быть достаточным основанием для принятия гипотезы. Если же опытные данные плохо согласуются с теоретически ожидаемыми, возникает большое сомнение в правильности предложенной гипотезы.
Степень соответствия фактических данных ожидаемым (гипотетическим) измеряется критерием соответствия хи-квадрат:
фактически наблюдаемое значение признака вi- той;теоретически ожидаемое число или признак (показатель) для данной группы,k число групп данных.
Критерий был предложен К.Пирсоном в 1900 г. и иногда его называют критерием Пирсона.
Задача. Среди 164 детей, наследовавших от одного из родителей фактор, а от другогофактор, оказалось 46 детей с фактором, 50с фактором, 68с тем и другим,. Рассчитать ожидаемые частоты при отношении 1:2:1 между группами и определить степень соответствия эмпирических данных с помощью критерия Пирсона.
Решение: Отношение наблюдаемых частот 46:68:50, теоретически ожидаемых 41:82:41.
Зададимся уровнем значимости равным 0,05. Табличное значение критерия Пирсона для этого уровня значимости при числе степеней свободы, равном оказалось равным 5,99. Следовательно гипотезу о соответствии экспериментальных данных теоретическим можно принять, так как, .
Отметим, что при вычислении критерия хи-квадрат мы уже не ставим условия о непременной нормальности распределения. Критерий хи-квадрат может использоваться для любых распределений, которые мы вольны сами выбирать в своих предположениях. В этом есть некоторая универсальность этого критерия.
Еще одно приложение критерия Пирсона это сравнение эмпирического распределения с нормальным распределением Гаусса. При этом он может быть отнесен к группе критериев проверки нормальности распределения. Единственным ограничением является тот факт, что общее число значений (вариант) при пользовании этим критерием должно быть достаточно велико (не менее 40), и число значений в отдельных классах (интервалах) должно быть не менее 5. В противном случае следует объединять соседние интервалы. Число степенй свободы при проверке нормальности распределения должно вычисляться как:.
Критерий Фишера.
Этот параметрический критерий служит для проверки нулевой гипотезы о равенстве дисперсий нормально распределенных генеральных совокупностей.
![]() Или.
Или.
При малых объемах выборок применение критерия Стьюдента может быть корректным только при условии равенства дисперсий. Поэтому прежде чем проводить проверку равенства выборочных средних значений, необходимо убедиться в правомочности использования критерия Стьюдента.
где N 1 , N 2 объемы выборок, 1 , 2 числа степеней свободы для этих выборок.
При пользовании таблицами следует обратить внимание, что число степеней свободы для выборки с большей по величине дисперсией выбирается как номер столбца таблицы, а для меньшей по величине дисперсии как номер строки таблицы.
Для уровня значимости по таблицам математической статистики находим табличное значение. Если, то гипотеза о равенстве дисперсий отклоняется для выбранного уровня значимости.
Пример. Изучали влияние кобальта на массу тела кроликов. Опыт проводился на двух группах животных: опытной и контрольной. Опытные получали добавку к рациону в виде водного раствора хлористого кобальта. За время опыта прибавки в весе составили в граммах:
|
Контроль |
|

Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .
Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
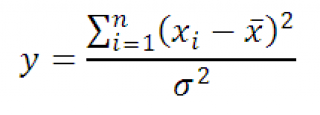
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:
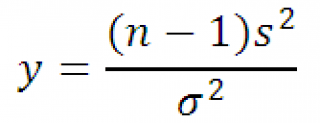
Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).