Chi-négyzet elosztási törvény. Pearson-eloszlás (khi-négyzet eloszlás)
A 19. század végéig a normál eloszlást tekintették az adatok univerzális variációs törvényének. K. Pearson azonban megjegyezte, hogy az empirikus frekvenciák nagymértékben eltérhetnek a normál eloszlástól. Felmerült a kérdés, hogyan lehet ezt bizonyítani. Nemcsak grafikus összehasonlításra volt szükség, ami szubjektív, hanem szigorú mennyiségi indoklásra is.
Így találták ki a kritériumot χ 2(chi-négyzet), amely az empirikus (megfigyelt) és az elméleti (várható) gyakoriságok közötti eltérés jelentőségét teszteli. Ez még 1900-ban történt, de a kritérium ma is használatos. Ezenkívül számos probléma megoldására lett adaptálva. Először is ez a kategorikus adatok elemzése, azaz. azokat, amelyeket nem a mennyiség, hanem a valamilyen kategóriába való tartozás fejez ki. Például az autó osztálya, a kísérletben résztvevő neme, a növény típusa stb. Matematikai műveletek, mint az összeadás és a szorzás, nem alkalmazhatók ilyen adatokra, ezekre csak a gyakoriság számítható.
Jelöljük a megfigyelt frekvenciákat Névjegy (megfigyelt), várt - E (várható). Példaként vegyük a kocka 60-szoros dobásának eredményét. Ha szimmetrikus és egyenletes, akkor annak a valószínűsége, hogy bármelyik oldalt megkapjuk, 1/6, ezért az egyes oldalak megszerzésének várható száma 10 (1/6∙60). A megfigyelt és a várt gyakoriságokat táblázatba írjuk és hisztogramot rajzolunk.

A nullhipotézis az, hogy a gyakoriságok konzisztensek, vagyis a tényleges adatok nem mondanak ellent a várt adatoknak. Alternatív hipotézis, hogy a gyakorisági eltérések túlmutatnak a véletlenszerű ingadozásokon, az eltérések statisztikailag szignifikánsak. Ahhoz, hogy szigorú következtetést vonjunk le, szükségünk van.
- A megfigyelt és a várt gyakoriságok közötti eltérés összefoglaló mértéke.
- Ennek a mértéknek az eloszlása, ha igaz az a hipotézis, hogy nincsenek különbségek.
Kezdjük a frekvenciák közötti távolsággal. Ha csak veszed a különbséget O-E, akkor egy ilyen mérték az adatok skálájától (gyakoriságától) függ. Például 20 - 5 = 15 és 1020 - 1005 = 15. A különbség mindkét esetben 15. De az első esetben a várható gyakoriságok 3-szor kisebbek, mint a megfigyeltek, a második esetben pedig csak 1,5 %. Szükségünk van egy relatív mértékre, amely nem függ a léptéktől.
Figyeljünk a következő tényekre. Általánosságban elmondható, hogy azoknak a kategóriáknak a száma, amelyekbe a frekvenciákat mérik, sokkal nagyobb lehet, így meglehetősen kicsi annak a valószínűsége, hogy egyetlen megfigyelés valamelyik kategóriába kerüljön. Ha igen, akkor egy ilyen valószínűségi változó eloszlása megfelel a ritka események törvényének, az úgynevezett Poisson törvénye. A Poisson-törvényben, mint ismeretes, a matematikai elvárás és a variancia értéke egybeesik (paraméter λ ). Ez azt jelenti, hogy a várható gyakoriság a névleges változó valamely kategóriájára vonatkozóan E i egyidejű lesz és annak szóródása. Ezen túlmenően a Poisson-törvény általában normális, sok megfigyelés esetén. E két tényt kombinálva azt kapjuk, hogy ha a megfigyelt és a várt gyakoriságok közötti egyezésre vonatkozó hipotézis helyes, akkor nagyszámú megfigyeléssel, kifejezés
Fontos megjegyezni, hogy a normalitás csak kellően magas frekvencián jelenik meg. A statisztikában általánosan elfogadott, hogy a megfigyelések teljes számának (a gyakoriságok összegének) legalább 50-nek kell lennie, és a várható gyakoriságnak minden fokozatban legalább 5-nek kell lennie. Csak ebben az esetben a fent látható érték szabványos normális eloszlású. . Tegyük fel, hogy ez a feltétel teljesül.
A normál normál eloszlásnak szinte minden értéke ±3-on belül van (a három szigma szabály). Így megkaptuk a gyakoriságok relatív különbségét egy gradációra. Egy általánosítható mértékre van szükségünk. Nem lehet csak összeadni az összes eltérést – 0-t kapunk (találd ki, miért). Pearson javasolta ezen eltérések négyzeteinek összeadását.
![]()
Ez a jel Khi-négyzet teszt Pearson. Ha a gyakoriságok valóban megfelelnek a vártnak, akkor a kritérium értéke viszonylag kicsi lesz (mivel a legtöbb eltérés nulla körül van). De ha a kritérium nagynak bizonyul, akkor ez jelentős különbségeket jelez a frekvenciák között.
A Pearson-kritérium akkor válik „nagy”-vá, ha ilyen vagy még nagyobb érték előfordulása valószínűtlenné válik. És egy ilyen valószínűség kiszámításához ismerni kell a kritérium eloszlását, amikor a kísérletet sokszor megismétlik, amikor a gyakorisági egyezés hipotézise helyes.
Amint az könnyen belátható, a khi-négyzet értéke a tagok számától is függ. Minél többen vannak, annál nagyobb értékkel kell rendelkeznie a feltételnek, mert minden tag hozzá fog járulni az összeghez. Ezért minden mennyiségre független feltételekkel, lesz saját terjesztése. Kiderült, hogy χ 2 disztribúciók egész családja.
És elérkeztünk egy kényes pillanathoz. Mi az a szám független feltételek? Úgy tűnik, hogy minden kifejezés (azaz eltérés) független. K. Pearson is így gondolta, de kiderült, hogy tévedett. Valójában a független tagok száma eggyel kevesebb lesz, mint a nominális változó gradációinak száma n. Miért? Mert ha van egy mintánk, amelyre a gyakoriságok összegét már kiszámoltuk, akkor az egyik gyakoriság mindig meghatározható a teljes szám és az összes többi összege közötti különbségként. Így a szórás valamivel kisebb lesz. Ronald Fisher 20 évvel azután vette észre ezt a tényt, hogy Pearson kidolgozta a kritériumát. Még az asztalokat is újra kellett készíteni.
Ebből az alkalomból Fisher egy új fogalmat vezetett be a statisztikába - a szabadság foka(szabadságfok), amely a független tagok számát jelenti az összegben. A szabadságfok fogalmának matematikai magyarázata van, és csak a normálhoz kapcsolódó eloszlásokban jelenik meg (Student, Fisher-Snedecor és maga a khi-négyzet).
Hogy jobban megértsük a szabadsági fokok jelentését, forduljunk egy fizikai analóghoz. Képzeljünk el egy pontot, amely szabadon mozog a térben. 3 szabadságfoka van, mert a háromdimenziós térben bármilyen irányba mozoghat. Ha egy pont bármely felület mentén mozog, akkor már két szabadságfoka van (oda-hátra, balra és jobbra), bár továbbra is háromdimenziós térben van. Egy rugó mentén mozgó pont ismét háromdimenziós térben van, de csak egy szabadságfokkal rendelkezik, mert előre vagy hátra mozoghat. Mint látható, az a tér, ahol az objektum található, nem mindig felel meg a valódi mozgásszabadságnak.
Körülbelül ugyanígy előfordulhat, hogy egy statisztikai ismérv megoszlása kisebb számú elemtől is függ, mint amennyi a kiszámításához szükséges tagok száma. Általában a szabadsági fokok száma kevesebb, mint a megfigyelések száma a meglévő függőségek számával.
Így a chi-négyzet eloszlás ( χ 2) eloszlások családja, amelyek mindegyike a szabadsági fok paramétereitől függ. A khi-négyzet próba formális definíciója pedig a következő. terjesztés χ 2(khi-négyzet) s k szabadsági fok a négyzetösszeg eloszlása k független standard normál valószínűségi változók.
Ezután áttérhetnénk magára a képletre, amellyel a khi-négyzet eloszlásfüggvényt számítjuk, de szerencsére már régen mindent kiszámoltak nekünk. Az érdeklődés valószínűségének meghatározásához használhatja a megfelelő statisztikai táblázatot vagy egy kész függvényt az Excelben.
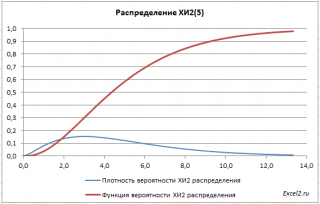
Érdekes látni, hogyan változik a khi-négyzet eloszlás alakja a szabadságfokok számától függően.

A szabadságfok növekedésével a khi-négyzet eloszlás általában normális. Ezt magyarázza a centrális határeloszlás tétele, amely szerint nagyszámú független valószínűségi változó összege normális eloszlású. Nem mond semmit a négyzetekről)).
A hipotézis tesztelése Pearson khi-négyzet próbával
Most elérkezünk a hipotézisek khi-négyzet módszerrel történő teszteléséhez. Általában a technológia marad. A nullhipotézis az, hogy a megfigyelt gyakoriságok megfelelnek a várt gyakoriságoknak (azaz nincs különbség köztük, mert ugyanabból a sokaságból származnak). Ha ez így van, akkor a szórás viszonylag kicsi lesz, a véletlenszerű ingadozások határain belül. A diszperzió mértékét a khi-négyzet teszt segítségével határozzuk meg. Ezután vagy magát a kritériumot hasonlítjuk össze a kritikus értékkel (a megfelelő szignifikanciaszintre és szabadsági fokra), vagy ami még helyesebb, kiszámítjuk a megfigyelt p-értéket, pl. annak a valószínűsége, hogy azonos vagy még nagyobb kritériumértéket kapunk, ha igaz a nullhipotézis.

Mert a frekvenciák egyezése érdekel, akkor a hipotézist elvetjük, ha a kritérium nagyobb, mint a kritikus szint. Azok. a kritérium egyoldalú. Néha (néha) azonban szükséges a bal oldali hipotézis tesztelése. Például amikor az empirikus adatok nagyon hasonlítanak az elméleti adatokhoz. Ekkor a kritérium egy valószínűtlen tartományba eshet, de a bal oldalon. Az a tény, hogy természetes körülmények között valószínűtlen, hogy olyan frekvenciákat kapjunk, amelyek gyakorlatilag egybeesnek az elméletivel. Mindig van valami véletlenszerűség, ami hibát okoz. De ha nincs ilyen hiba, akkor talán meghamisították az adatokat. De ennek ellenére a jobb oldali hipotézist általában tesztelik.
Térjünk vissza a kockaproblémához. Számítsuk ki a rendelkezésre álló adatok felhasználásával a khi-négyzet próba értékét.
Most keressük meg a kritikus értéket 5 szabadságfoknál ( k) és szignifikancia szint 0,05 ( α ) a chi-négyzet eloszlás kritikus értékeinek táblázata szerint.

Vagyis a 0,05-ös kvantilis egy chi négyzetes eloszlás (jobb farok), 5 szabadságfokkal χ 2 0,05; 5 = 11,1.
Hasonlítsuk össze a tényleges és a táblázatos értékeket. 3,4 ( χ 2) < 11,1 (χ 2 0,05; 5). A számított kritérium kisebbnek bizonyult, ami azt jelenti, hogy a gyakoriságok egyenlőségének (egyezésének) hipotézisét nem utasítják el. Az ábrán a helyzet így néz ki.

Ha a számított érték a kritikus tartományba esne, a nullhipotézist elvetjük.
Helyesebb lenne a p-értéket is kiszámítani. Ehhez meg kell találni a táblázatban a legközelebbi értéket adott számú szabadsági fokhoz, és meg kell nézni a megfelelő szignifikancia szintet. De ez a múlt század. Számítógépet fogunk használni, különösen MS Excelt. Az Excelnek számos, a chi-négyzethez kapcsolódó függvénye van.

Az alábbiakban rövid leírásuk olvasható.
CH2.OBR– a kritérium kritikus értéke adott valószínűség mellett a bal oldalon (mint a statisztikai táblázatokban)
CH2.OBR.PH– a kritérium kritikus értéke adott valószínűséghez a jobb oldalon. A függvény lényegében megduplázza az előzőt. De itt azonnal jelezheti a szintet α , ahelyett, hogy kivonnánk 1-ből. Ez kényelmesebb, mert a legtöbb esetben a disztribúció jobb oldalára van szükség.
CH2.DIST– p-érték a bal oldalon (sűrűség számítható).
CH2.DIST.PH– p-érték a jobb oldalon.
CHI2.TESZT– azonnal elvégzi a khi-négyzet tesztet két frekvenciatartományra. A szabadsági fokok számát eggyel kisebbnek vesszük, mint az oszlopban lévő frekvenciák számát (ahogyan lennie kell), így p-értéket adunk vissza.
Számítsuk ki kísérletünkhöz a kritikus (táblázatos) értéket 5 szabadságfokra és alfa 0,05-re. Az Excel képlet így fog kinézni:
CH2.OBR(0,95;5)
CH2.OBR.PH(0,05;5)
Az eredmény ugyanaz lesz - 11.0705. Ez az az érték, amelyet a táblázatban látunk (1 tizedesjegyre kerekítve).
Végezetül számítsuk ki az 5 szabadságfok kritérium p-értékét χ 2= 3.4. Szükségünk van a jobb oldali valószínűségre, ezért a függvényt HH (jobb farok) hozzáadásával vesszük fel.
CH2.DIST.PH(3,4;5) = 0,63857
Ez azt jelenti, hogy 5 szabadságfok mellett a kritériumérték megszerzésének valószínűsége az χ 2= 3,4 és több, majdnem 64%. Természetesen a hipotézist nem utasítják el (p-érték nagyobb, mint 5%), a gyakoriságok nagyon jó egyezést mutatnak.
Most nézzük meg a gyakoriságok egyezéséről szóló hipotézist a khi-négyzet teszt és a CHI2.TESZT Excel függvény segítségével.

Nincsenek táblázatok, nincsenek nehézkes számítások. Ha a megfigyelt és várt gyakoriságú oszlopokat függvényargumentumként adjuk meg, azonnal megkapjuk a p-értéket. Szépség.
Most képzeld el, hogy egy gyanús sráccal kockajátékot játszol. A pontok eloszlása 1-től 5-ig változatlan, de 26 hatost dob (a dobások száma összesen 78 lesz).

A p-érték ebben az esetben 0,003-nak bizonyul, ami sokkal kisebb, mint 0,05. Jó okunk van kételkedni a kocka érvényességében. Így néz ki ez a valószínűség egy khi-négyzet eloszlási diagramon.

Maga a khi-négyzet kritérium itt 17,8-nak bizonyul, ami természetesen nagyobb, mint a táblázatban szereplő (11,1).
Remélem sikerült elmagyaráznom, mi az egyetértés kritériuma χ 2(Pearson khi-négyzet), és hogyan használható statisztikai hipotézisek tesztelésére.
Végül még egyszer egy fontos feltételről! A khi-négyzet teszt csak akkor működik megfelelően, ha az összes frekvencia száma meghaladja az 50-et, és az egyes fokozatok minimális várható értéke nem kevesebb, mint 5. Ha bármely kategóriában a várható gyakoriság kisebb, mint 5, de az összes frekvencia összege meghaladja az 5-öt. 50, akkor az ilyen kategóriát a legközelebbivel kombináljuk úgy, hogy összgyakorisága meghaladja az 5-öt. Ha ez nem lehetséges, vagy a gyakoriságok összege kisebb, mint 50, akkor pontosabb hipotézisvizsgálati módszereket kell alkalmazni. Majd máskor beszélünk róluk.
Az alábbiakban egy videót láthat arról, hogyan tesztelhet egy hipotézist Excelben a khi-négyzet teszt segítségével.
A khi-négyzet eloszlás az egyik legszélesebb körben használt statisztika a statisztikai hipotézisek tesztelésére. A khi-négyzet eloszlás alapján megalkotják az egyik legerősebb illeszkedési tesztet - a Pearson khi-négyzet tesztet.
Az egyezés kritériuma az ismeretlen eloszlás feltételezett törvényére vonatkozó hipotézis tesztelésének kritériuma.
A χ2 (khi-négyzet) teszt a különböző eloszlások hipotézisének tesztelésére szolgál. Ez az ő méltósága.
A kritérium számítási képlete egyenlő
ahol m és m’ empirikus, illetve elméleti frekvenciák
a kérdéses elosztás;
n a szabadságfokok száma.
Az ellenőrzéshez össze kell hasonlítanunk az empirikus (megfigyelt) és az elméleti (normális eloszlás feltételezésével számolt) gyakoriságokat.
Ha az empirikus gyakoriságok teljesen egybeesnek a számított vagy várt gyakorisággal, akkor S (E – T) = 0 és a χ2 kritérium is nulla lesz. Ha S (E – T) nem egyenlő nullával, ez eltérést jelez a sorozat számított gyakoriságai és tapasztalati gyakoriságai között. Ilyen esetekben értékelni kell a χ2 kritérium jelentőségét, amely elméletileg nullától a végtelenig változhat. Ez úgy történik, hogy a ténylegesen kapott χ2ф értékét összehasonlítják a kritikus értékével (χ2st) A nullhipotézist, vagyis azt a feltételezést, hogy az empirikus és az elméleti vagy várható gyakoriságok közötti eltérés véletlenszerű, megcáfolódik, ha χ2ф nagyobb vagy egyenlő, mint χ2st az elfogadott szignifikanciaszintre (a) és a szabadsági fokok számára (n).
A χ2 valószínűségi változó valószínű értékeinek eloszlása folytonos és aszimmetrikus. A szabadsági fokok számától (n) függ, és a megfigyelések számának növekedésével megközelíti a normális eloszlást. Ezért a χ2 kritérium alkalmazása a diszkrét eloszlások értékelésére bizonyos hibákkal jár, amelyek befolyásolják annak értékét, különösen kis mintákban. A pontosabb becslések érdekében a variációs sorozatba osztott mintának legalább 50 opciót kell tartalmaznia. A χ2 kritérium helyes alkalmazása azt is megköveteli, hogy az extrém osztályok változatainak gyakorisága ne legyen kisebb 5-nél; ha 5-nél kevesebb van belőlük, akkor azokat a szomszédos osztályok gyakoriságaival kombináljuk úgy, hogy a teljes összeg 5-nél nagyobb vagy egyenlő legyen. A gyakoriságok kombinációjának megfelelően az osztályok száma (N) csökken. A szabadsági fokok számát a másodlagos osztályok száma határozza meg, figyelembe véve a variációs szabadság korlátozásainak számát.
Mivel a χ2 kritérium meghatározásának pontossága nagymértékben függ az elméleti frekvenciák (T) számítási pontosságától, ezért az empirikus és a számított frekvenciák közötti különbség meghatározásához kerekítetlen elméleti frekvenciákat kell használni.
Példaként vegyünk egy, a statisztikai módszerek bölcsészettudományi alkalmazásának szentelt honlapon megjelent tanulmányt.
A Khi-négyzet teszt lehetővé teszi a gyakorisági eloszlások összehasonlítását, függetlenül attól, hogy normális eloszlásúak-e vagy sem.
A gyakoriság egy esemény előfordulásának számát jelenti. Az események előfordulási gyakoriságával általában akkor foglalkozunk, amikor a változókat egy névskálán mérjük, és a gyakoriságon kívül egyéb jellemzőik kiválasztása lehetetlen vagy problémás. Más szóval, amikor egy változónak minőségi jellemzői vannak. Emellett sok kutató hajlamos a teszteredményeket szintekre konvertálni (magas, átlagos, alacsony), és táblázatokat készít a pontszámok eloszlásáról, hogy megtudja, hány ember van ezeken a szinteken. Annak bizonyítására, hogy valamelyik szinten (valamelyik kategóriában) valóban nagyobb (kevesebb) a létszám, a Khi-négyzet együtthatót is alkalmazzák.
Nézzük a legegyszerűbb példát.
Fiatalabb serdülők körében végeztek tesztet az önbecsülés azonosítására. A teszteredményeket három szintre konvertálták: magas, közepes, alacsony. A frekvenciák a következőképpen oszlanak meg:
Magas (B) 27 fő.
Átlagos (C) 12 fő.
Alacsony (L) 11 fő
Nyilvánvaló, hogy a gyerekek többsége magas önbecsüléssel rendelkezik, de ezt statisztikailag bizonyítani kell. Ehhez a Khi-négyzet tesztet használjuk.
Feladatunk annak ellenőrzése, hogy a kapott empirikus adatok eltérnek-e az elméletileg egyformán valószínű adatoktól. Ehhez meg kell találni az elméleti frekvenciákat. Esetünkben az elméleti gyakoriságok egyformán valószínű gyakoriságok, amelyeket úgy kapunk meg, hogy az összes gyakoriságot összeadjuk és elosztjuk a kategóriák számával.
A mi esetünkben:
(B + C + H)/3 = (27+12+11)/3 = 16,6
A khi-négyzet próba kiszámításának képlete:
χ2 = ∑(E - T)I/T
A táblázatot elkészítjük:
Keresse meg az utolsó oszlop összegét:
Most meg kell találnia a kritérium kritikus értékét a kritikus értékek táblázata segítségével (1. táblázat a függelékben). Ehhez szükségünk van a szabadsági fokok számára (n).
n = (R - 1) * (C - 1)
ahol R a táblázat sorainak száma, C az oszlopok száma.
Esetünkben csak egy oszlop (értsd: az eredeti empirikus gyakoriságok) és három sor (kategória) van, így a képlet megváltozik - az oszlopokat kizárjuk.
n = (R-1) = 3-1 = 2
A p≤0,05 hibavalószínűség és n = 2 esetén a kritikus érték χ2 = 5,99.
A kapott tapasztalati érték nagyobb, mint a kritikus érték – a gyakorisági különbségek szignifikánsak (χ2= 9,64; p≤0,05).
Amint láthatja, a kritérium kiszámítása nagyon egyszerű, és nem vesz sok időt. A khi-négyzet teszt gyakorlati értéke óriási. Ez a módszer a legértékesebb a kérdőívekre adott válaszok elemzésekor.
Nézzünk egy összetettebb példát.
Például egy pszichológus azt szeretné tudni, hogy igaz-e, hogy a tanárok elfogultabbak a fiúkkal, mint a lányokkal szemben. Azok. nagyobb valószínűséggel dicsérik a lányokat. Ehhez a pszichológus a tanulók jellemzőit elemezte három szó előfordulási gyakoriságára: „aktív”, „szorgalmas”, „fegyelmezett”, és a szavak szinonimáit is megszámolta. A szavak előfordulási gyakoriságára vonatkozó adatok bekerültek a táblázatba:
A kapott adatok feldolgozásához a khi-négyzet tesztet használjuk.
Ehhez elkészítjük az empirikus gyakoriságok eloszlásának táblázatát, azaz. az általunk megfigyelt frekvenciák:
Elméletileg arra számítunk, hogy a frekvenciák egyenletesen oszlanak el, pl. a gyakoriság arányosan oszlik el fiúk és lányok között. Készítsünk egy táblázatot az elméleti frekvenciákról. Ehhez meg kell szorozni a sor összegét az oszlop összegével, és a kapott számot el kell osztani a teljes összeggel (s).
A számítások végső táblázata így fog kinézni:
χ2 = ∑(E - T)I/T
n = (R - 1), ahol R a táblázat sorainak száma.
Esetünkben khi-négyzet = 4,21; n = 2.
A kritérium kritikus értékeinek táblázatát használva azt találjuk, hogy n = 2 és 0,05 hibaszint mellett a kritikus érték χ2 = 5,99.
A kapott érték kisebb, mint a kritikus érték, ami azt jelenti, hogy a nullhipotézis elfogadott.
Következtetés: a tanárok nem tulajdonítanak jelentőséget a gyermek nemének, amikor jellemzőket írnak neki.
Következtetés.
K. Pearson jelentős mértékben hozzájárult a matematikai statisztika (nagyszámú alapvető fogalom) fejlődéséhez. Pearson fő filozófiai álláspontja a következőképpen fogalmazódik meg: a tudomány fogalmai mesterséges konstrukciók, az érzékszervi tapasztalatok leírásának és rendezésének eszközei; a tudományos mondatokba kapcsolásának szabályait a tudomány grammatikája, azaz a tudományfilozófia izolálja. Az univerzális diszciplína - az alkalmazott statisztika - lehetővé teszi, hogy egymástól eltérő fogalmakat és jelenségeket kapcsoljunk össze, bár Pearson szerint ez szubjektív.
K. Pearson konstrukciói közül sok közvetlenül kapcsolódik egymáshoz, vagy antropológiai anyagok felhasználásával fejlesztették ki. Számos numerikus osztályozási módszert és statisztikai kritériumot dolgozott ki, amelyeket a tudomány minden területén alkalmaznak.
Irodalom.
1. Bogolyubov A. N. Matematika. Mechanika. Életrajzi kézikönyv. - Kijev: Naukova Dumka, 1983.
2. Kolmogorov A. N., Juskevics A. P. (szerk.). A 19. század matematikája. - M.: Tudomány. - T. I.
3. 3. Borovkov A.A. Matek statisztika. M.: Nauka, 1994.
4. 8. Feller V. Bevezetés a valószínűségelméletbe és alkalmazásaiba. - M.: Mir, T.2, 1984.
5. 9. Harman G., Modern faktoranalízis. - M.: Statisztika, 1972.
Pearson (khi-négyzet), Student és Fisher eloszlások
A normál eloszlás felhasználásával három olyan eloszlást definiálunk, amelyeket ma már gyakran használnak a statisztikai adatfeldolgozásban. Ezek a disztribúciók sokszor megjelennek a könyv későbbi részeiben.
Pearson-eloszlás (chi - négyzet) – egy valószínűségi változó eloszlása
hol vannak a valószínűségi változók x 1 , x 2 ,…, Xn függetlenek és azonos eloszlásúak N(0,1). Ebben az esetben a kifejezések száma, pl. n, a khi-négyzet eloszlás „szabadságfokainak száma”.
A khi-négyzet eloszlást a variancia becslésénél (konfidencia-intervallum használatával), az egyezés, homogenitás, függetlenség hipotéziseinek tesztelésekor, elsősorban véges számú értéket felvevő kvalitatív (kategorizált) változók esetén, valamint számos egyéb statisztikai adatfeladatnál alkalmazzuk. elemzés.
terjesztés t Student-féle t egy valószínűségi változó eloszlása
hol vannak a valószínűségi változók UÉs x független, U szabványos normál eloszlású N(0,1), és x– chi eloszlás – négyzet c n szabadsági fokokat. Ahol n a Student-eloszlás „szabadságfokainak száma”.
A Student disztribúciót 1908-ban vezette be W. Gosset angol statisztikus, aki egy sörgyárban dolgozott. Ebben a gyárban valószínűségszámítási és statisztikai módszereket alkalmaztak a gazdasági és műszaki döntések meghozatalára, ezért a vezetése megtiltotta V. Gosset-nek, hogy saját neve alatt publikáljon tudományos cikkeket. Ily módon a V. Gosset által kidolgozott valószínűségi és statisztikai módszerek formájában megvédték az üzleti titkokat és a „know-how-t”. Lehetősége volt azonban „Diák” álnéven publikálni. A Gosset-Student története azt mutatja, hogy Nagy-Britanniában már száz évvel ezelőtt is tisztában voltak a menedzserek a valószínűségi-statisztikai módszerek nagyobb gazdasági hatékonyságával.
Jelenleg a Student-eloszlás az egyik legismertebb eloszlás, amelyet valós adatok elemzésére használnak. A matematikai várakozás, az előrejelzési érték és egyéb jellemzők konfidenciaintervallumokkal történő becslésére, a matematikai elvárások értékeivel kapcsolatos hipotézisek tesztelésére, regressziós együtthatókra, a minta homogenitásának hipotéziseire stb. .
A Fisher-eloszlás egy valószínűségi változó eloszlása
hol vannak a valószínűségi változók X 1És X 2 függetlenek és khi-négyzet eloszlásúak a szabadsági fokok számával k 1 És k 2 illetőleg. Ugyanakkor a pár (k 1 , k 2 ) – a Fisher-eloszlás „szabadságfokának” párja, nevezetesen, k 1 a számláló szabadságfokainak száma, és k 2 – a nevező szabadságfokainak száma. Valószínűségi változó eloszlása F R. Fisher (1890-1962) nagy angol statisztikusról nevezték el, aki aktívan használta munkáiban.
A Fisher-eloszlást a modell regresszióanalízisben, a varianciaegyenlőségben és az alkalmazott statisztika egyéb problémáiban való megfelelőségére vonatkozó hipotézisek tesztelésére használják.
A khi-négyzet, a Student és Fisher eloszlásfüggvények kifejezései, azok sűrűsége és jellemzői, valamint a gyakorlati használatukhoz szükséges táblázatok megtalálhatók a szakirodalomban (lásd pl.).
A biológiai jelenségek kvantitatív vizsgálata szükségszerűen megköveteli olyan hipotézisek felállítását, amelyekkel ezeket a jelenségeket megmagyarázzuk. Egy adott hipotézis teszteléséhez speciális kísérletek sorozatát hajtják végre, és a kapott tényleges adatokat összehasonlítják az e hipotézis szerint elméletileg várt adatokkal. Ha van egybeesés, ez elegendő ok lehet a hipotézis elfogadására. Ha a kísérleti adatok nem egyeznek jól az elméletileg várt adatokkal, nagy kétség merül fel a felállított hipotézis helyességével kapcsolatban.
Azt, hogy a tényleges adatok mennyire felelnek meg a vártnak (hipotetikusnak), a khi-négyzet teszttel mérjük:
- a jellemző tényleges megfigyelt értéke in én- hogy; egy adott csoportra elméletileg várható szám vagy jel (mutató), k-adatcsoportok száma.
A kritériumot K. Pearson javasolta 1900-ban, és néha Pearson-kritériumnak is nevezik.
Feladat. Az egyik szülőtől faktort, a másiktól faktort örökölt 164 gyermek között 46 faktoros, 50 faktoros, 68 mindkettőben szenvedő gyermek volt. Számítsa ki a várható gyakoriságokat a csoportok közötti 1:2:1 arányhoz, és határozza meg az empirikus adatok egyezési fokát a Pearson-próba segítségével.
Megoldás: A megfigyelt gyakoriságok aránya 46:68:50, elméletileg 41:82:41.
Állítsuk a szignifikanciaszintet 0,05-re. A Pearson-kritérium táblázatértéke erre a szignifikanciaszintre egyenlő szabadságfokszámmal 5,99 lett. Ezért a kísérleti adatok elméleti adatoknak való megfelelésére vonatkozó hipotézis elfogadható, mivel, .
Vegyük észre, hogy a khi-négyzet próba kiszámításakor már nem szabjuk meg az eloszlás nélkülözhetetlen normalitásának feltételeit. A khi-négyzet tesztet bármilyen eloszlásra használhatjuk, amelyet szabadon választhatunk a feltételezéseinkben. Ennek a kritériumnak van némi univerzalitása.
A Pearson-teszt másik alkalmazása az empirikus eloszlás összehasonlítása a Gauss-féle normális eloszlással. Sőt, az eloszlás normalitásának ellenőrzésére szolgáló kritériumok csoportjába sorolható. Az egyetlen korlátozás az a tény, hogy ennek a kritériumnak a használatakor az értékek (opciók) teljes számának elég nagynak kell lennie (legalább 40), és az értékek számának az egyes osztályokban (intervallumokban) legalább 5-nek kell lennie. Ellenkező esetben a szomszédos intervallumokat kombinálni kell. Az eloszlás normalitásának ellenőrzésekor a szabadságfokok számát a következőképpen kell kiszámítani:.
Fisher-kritérium.
Ez a paraméteres teszt annak a nullhipotézisnek a tesztelésére szolgál, amely szerint a normál eloszlású populációk szórása egyenlő.
![]() Vagy.
Vagy.
Kis mintaméretek esetén a Student-féle teszt használata csak akkor lehet helyes, ha az eltérések egyenlőek. Ezért a mintaátlagok egyenlőségének tesztelése előtt meg kell győződni a Student t teszt használatának érvényességéről.
Ahol N 1 , N 2 mintaméretek, 1 , 2 e minták szabadságfokainak száma.
Táblázatok használatakor ügyelni kell arra, hogy a nagyobb szórású mintánál a szabadságfok száma legyen a táblázat oszlopszáma, kisebb szórásnál pedig a táblázat sorszáma.
A szignifikanciaszinthez a matematikai statisztika táblázataiból találjuk meg a táblázat értékét. Ha, akkor a varianciaegyenlőség hipotézisét a kiválasztott szignifikanciaszintre elvetjük.
Példa. Vizsgálták a kobalt hatását a nyulak testtömegére. A kísérletet két állatcsoporton végezték: kísérleti és kontrollállatokon. A kísérleti alanyok étrend-kiegészítőt kaptak kobalt-klorid vizes oldata formájában. A kísérlet során a súlygyarapodás grammban volt:
|
Ellenőrzés |
|

Tekintsük a Khi-négyzet eloszlást. MS EXCEL függvény használataCH2.DIST() Ábrázoljuk az eloszlásfüggvényt és a valószínűségi sűrűséget, és magyarázzuk el ennek az eloszlásnak a matematikai statisztika céljára való felhasználását.
Khi-négyzet eloszlás (X 2, XI2, angolChi- négyzet alakúterjesztés) a matematikai statisztika különféle módszereiben használják:
- az építkezés során;
- nál nél ;
- at (az empirikus adatok megegyeznek-e az elméleti eloszlásfüggvényre vonatkozó feltételezésünkkel vagy sem, angol Goodness-of-fit)
- at (két kategorikus változó kapcsolatának meghatározására szolgál, angol chi-négyzet asszociációs teszt).
Meghatározás: Ha x 1 , x 2 , …, x n független valószínűségi változók N(0;1) eloszlásban, akkor az Y=x 1 2 + x 2 2 +…+ x n 2 valószínűségi változó eloszlása terjesztés X 2 n szabadságfokkal.
terjesztés X 2 nevezett paramétertől függ a szabadság foka (df, fokonnak,-nekszabadság). Például építéskor szabadsági fokok száma egyenlő df=n-1, ahol n a méret minták.
Eloszlási sűrűség X 2
képlettel kifejezve:
Függvénygrafikonok
terjesztés X 2 aszimmetrikus alakja van, egyenlő n-nel, egyenlő 2n-nel.
BAN BEN példafájlt a Grafikon lapon adott eloszlássűrűség grafikonok valószínűségek és kumulatív eloszlásfüggvény.
Hasznos ingatlan CH2 eloszlások
Legyenek x 1 , x 2 , …, x n független valószínűségi változók eloszlásban normális törvény azonos μ és σ paraméterekkel, és X av van számtani átlaga ezek az x értékek.
Aztán a valószínűségi változó y egyenlő
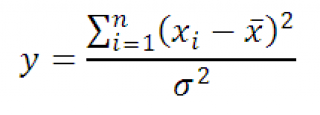
Megvan X 2 -terjesztés n-1 szabadságfokkal. A definíciót használva a fenti kifejezés a következőképpen írható át:
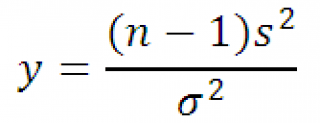
Ennélfogva, mintavételi eloszlás statisztika y, at minta tól től normális eloszlás, Megvan X 2 -terjesztés n-1 szabadságfokkal.
Erre az ingatlanra akkor lesz szükségünk. Mert diszperzió csak pozitív szám lehet, és X 2 -terjesztésértékelésére szolgál, akkor y d.b. >0, a definíció szerint.
CH2 eloszlás az MS EXCEL-ben
Az MS EXCEL-ben, a 2010-es verziótól kezdődően, for X 2 -elosztások van egy speciális CHISQ.DIST() függvény, amely lehetővé teszi a számítást valószínűségi sűrűség(lásd a fenti képletet) és (annak a valószínűsége, hogy egy X valószínűségi változó rendelkezik CI2-terjesztés, értéke kisebb vagy egyenlő, mint x, P(X<= x}).
jegyzet: Mert CH2 eloszlás speciális eset, akkor a képlet =GAMMA.ELTOLÁS(x;n/2;2;IGAZ) pozitív egész számra n ugyanazt az eredményt adja vissza, mint a képlet =CHI2.ELTOLÁS(x;n; IGAZ) vagy =1-CHI2.DIST.PH(x;n) . És a képlet =GAMMA.ELOSZTÁS(x;n/2;2;HAMIS) ugyanazt az eredményt adja vissza, mint a képlet =CHI2.ELTOLÁS(x;n; HAMIS), azaz valószínűségi sűrűség CH2 eloszlások.
A HI2.DIST.PH() függvény visszatér elosztási függvény, pontosabban a jobb oldali valószínűség, azaz. P(X > x). Nyilvánvaló, hogy az egyenlőség igaz
=CHI2.ELOSZ.PH(x;n)+CHI2.ELTOLÁS(x;n;IGAZ)=1
mert az első tag kiszámítja a P(X > x) valószínűséget, a második P(X<= x}.
Az MS EXCEL 2010 előtt az EXCEL-ben csak a CHIDIST() függvény volt, amely lehetővé teszi a jobb oldali valószínűség kiszámítását, pl. P(X > x). Az új MS EXCEL 2010 XI2.DIST() és XI2.DIST.PH() függvényeinek lehetőségei lefedik ennek a függvénynek a képességeit. A CH2DIST() függvény a kompatibilitás érdekében megmaradt az MS EXCEL 2010-ben.
A CHI2.DIST() az egyetlen függvény, amely visszatér a chi2 eloszlás valószínűségi sűrűsége(a harmadik argumentumnak HAMIS-nak kell lennie). A többi függvény visszatér kumulatív eloszlásfüggvény, azaz annak valószínűsége, hogy a valószínűségi változó értéket vesz fel a megadott tartományból: P(X<= x}.
A fenti MS EXCEL függvények a -ban vannak megadva.
Példák
Határozzuk meg annak a valószínűségét, hogy az X valószínűségi változó kisebb vagy egyenlő értéket vesz fel, mint a megadott x: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; IGAZ)
=1-HI2.ELTOL.PH(x; n)
=1-CHI2DIST(x; n)
A CH2.DIST.PH() függvény a P(X > x) valószínűséget adja vissza, az úgynevezett jobb oldali valószínűséget, így P(X)<= x}, необходимо вычесть ее результат от 1.
Határozzuk meg annak a valószínűségét, hogy az X valószínűségi változó nagyobb értéket vesz fel, mint egy adott x: P(X > x). Ez több funkcióval is megtehető:
1-CHI2.ELTOLÁS(x; n; IGAZ)
=HI2.ELTOL.PH(x; n)
=CHI2DIST(x; n)
Inverz chi2 eloszlásfüggvény
A számításhoz az inverz függvényt használjuk alfa- , azaz értékek kiszámításához x adott valószínűségre alfa, és x meg kell felelnie a P(X<= x}=alfa.
A számításhoz a CH2.INV() függvény szolgál a normális eloszlás varianciájának konfidencia intervallumai.
A CHI2.OBR.PH() függvény kiszámítására szolgál, azaz. ha egy szignifikanciaszintet adunk meg a függvény argumentumaként, például 0,05, akkor a függvény az x valószínűségi változó értékét adja vissza, amelyre P(X>x)=0,05. Összehasonlításképpen: a XI2.INR() függvény az x valószínűségi változó értékét adja vissza, amelyre P(X)<=x}=0,05.
Az MS EXCEL 2007 és korábbi verzióiban a HI2.OBR.PH() helyett a HI2OBR() függvényt használták.
A fenti funkciók felcserélhetők, mert a következő képletek ugyanazt az eredményt adják vissza:
=CHI.OBR(alpha;n)
=HI2.OBR.PH(1-alfa;n)
=CHI2INV(1- alfa;n)
A számításokra néhány példa található példafájlt a Funkciók lapon.
Az MS EXCEL a CH2 eloszlást használja
Az alábbiakban az orosz és az angol függvénynevek közötti megfelelés látható:
CH2.DIST.PH() - angol. név CHISQ.DIST.RT, azaz CHI-négyzet eloszlás jobb farok, a jobboldali Chi-négyzet(d) eloszlás
CH2.OBR() - angol. név CHISQ.INV, i.e. CHI-négyzet eloszlás INVerse
CH2.PH.OBR() - angol. név CHISQ.INV.RT, i.e. CHI-négyzet eloszlás INVerse jobb farok
CH2DIST() - angol. név CHIDIST, a CHISQ.DIST.RT-vel egyenértékű függvény
CH2OBR() - angol. név CHIINV, i.e. CHI-négyzet eloszlás INVerse
Eloszlási paraméterek becslése
Mert általában CH2 eloszlás matematikai statisztikai célokra használják (számítás konfidencia intervallumok, hipotézisek tesztelése stb.), valós értékek modelljeinek megalkotásához pedig szinte soha, akkor ennél az eloszlásnál az eloszlási paraméterek becslésének tárgyalása itt nem történik meg.
A CI2 eloszlás közelítése a normál eloszlással
n>30 szabadságfokszámmal elosztás X 2 jól közelítve normális eloszlás val vel átlagos értékμ=n és szórás σ=2*n (lásd példalapfájl Közelítés).